其他集群知识架构
# Redis专题
## 数据分区方案
### 客户端分区方案
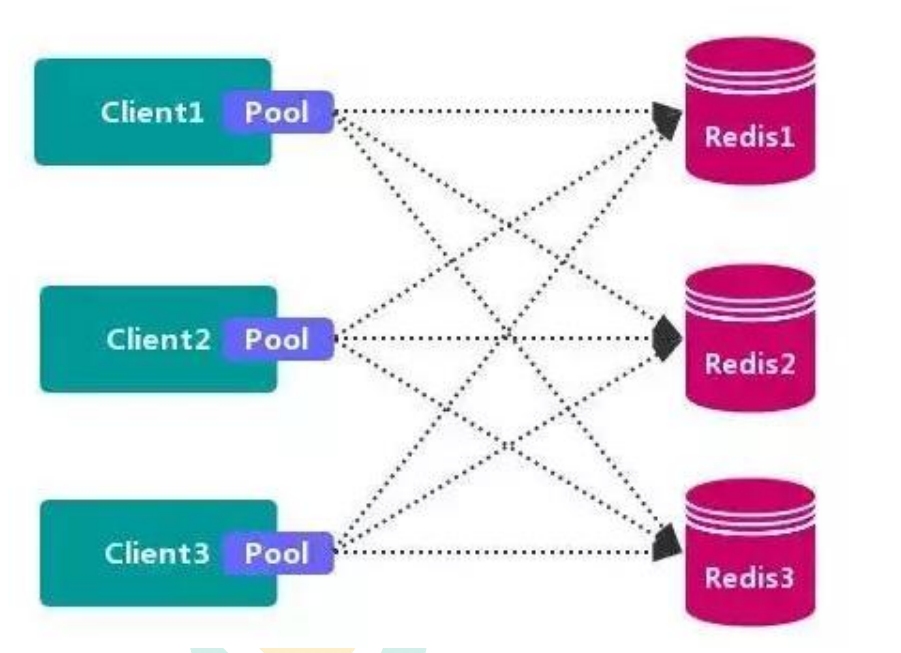
> 客户端分区方案 的代表为 Redis Sharding,Redis Sharding 是 Redis Cluster 出来之前 ,业界普遍使用的 Redis 多实例集群 方法。Java 的 Redis 客户端驱动库 Jedis,支持 RedisSharding 功能,即 ShardedJedis 以及 结合缓存池 的 ShardedJedisPool
> **个人理解: 这个客户端分区放哪类似于ShardingSphereJDBC**, 每一个客户端(应用都有一个自己的线程池), 我们通过配置这个线程池从而制定好分片方案, 将数据分片存储给不同的节点
#### 优点
> **不使用 第三方中间件**,分区逻辑 可控,**配置 简单**,节点之间无关联,容易 线性扩展,**灵活性强**。
#### 缺点
> 客户端 **无法 动态增删 服务节点**,客户端需要**自行维护 分发逻辑**,客户端之间 **无连接共享,会造成 连接浪费**。
1. 无法动态增删: 是因为我们在客户端已经配置好了分片逻辑, 贸然增删节点, 这个分片规则就废弃了, 如果还用这个规则, 新的节点无法访问, 过时的节点可能造成数据丢失, **这进一步说明了客户端分区的容错差**
### 代理分区方案
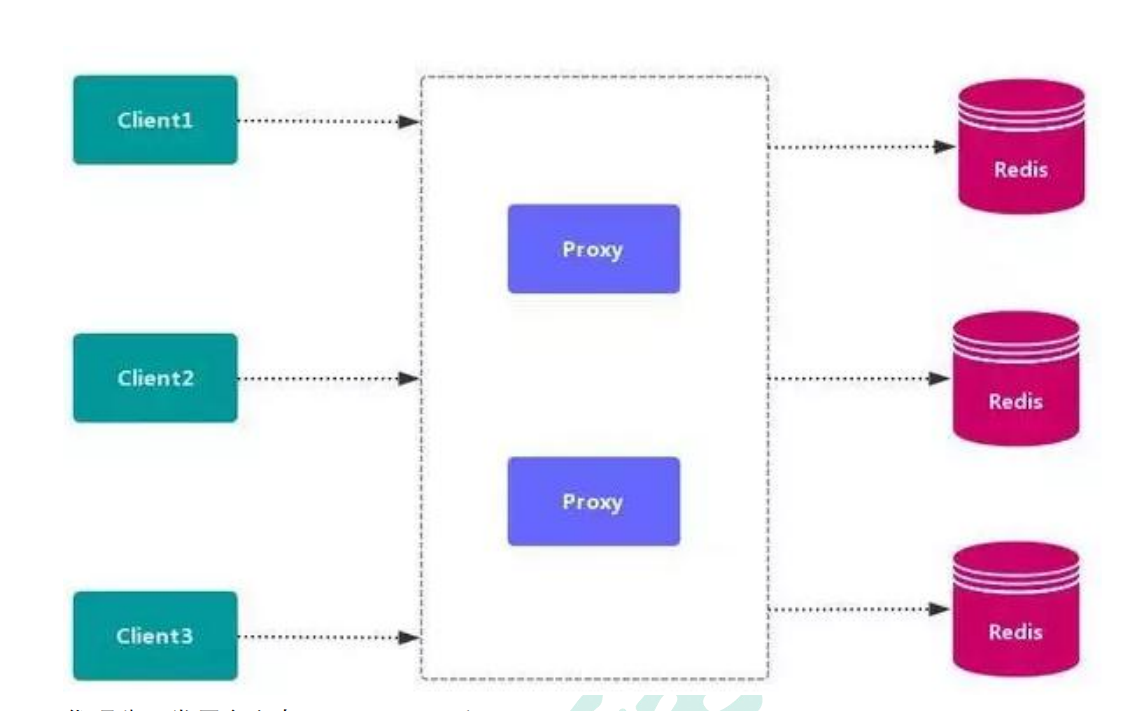
> 代理分区常用方案有 Twemproxy 和 Codis。
> 这个有点像**ShardingSphere-Proxy**
### RedisCluster
详情请到当前文档的下面
## 高可用方式
### Sentinel( 哨兵机制)支持高可用
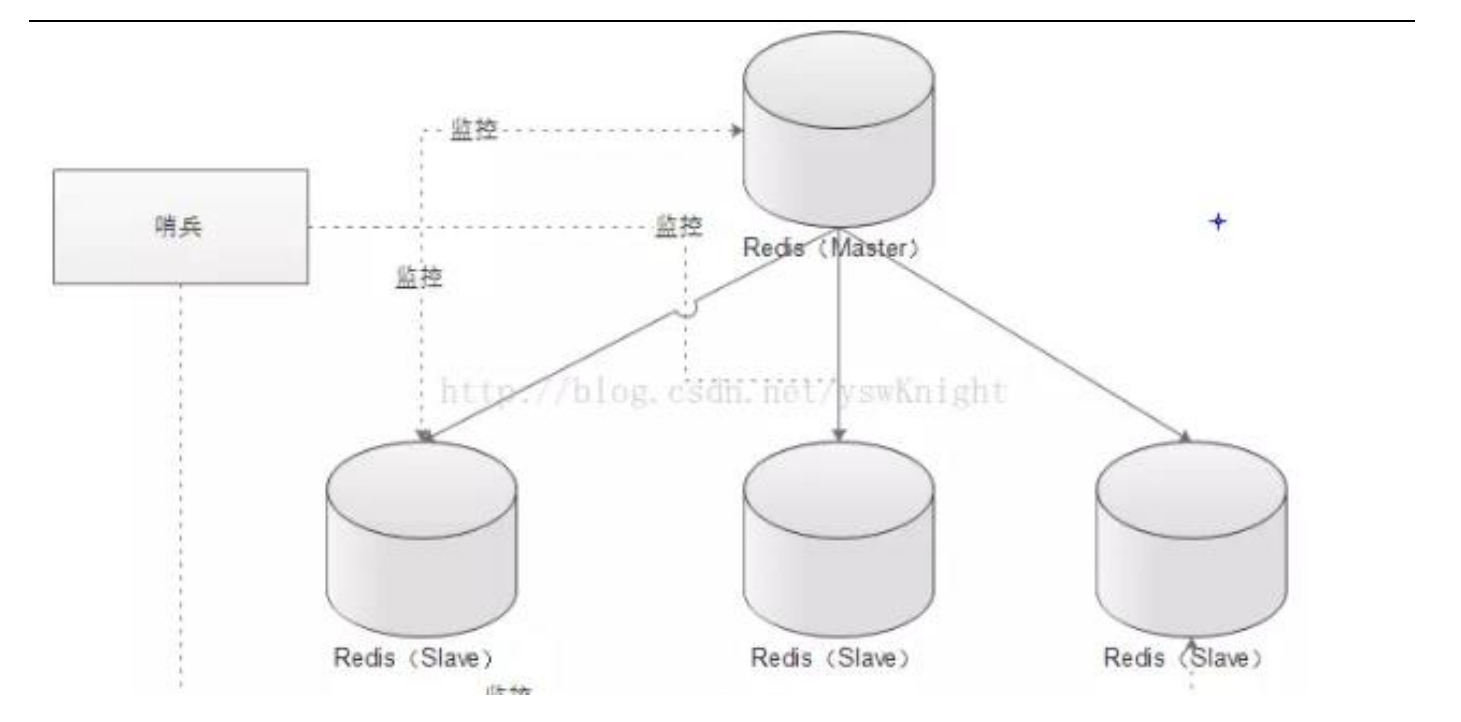
前面介绍了主从机制,但是从运维角度来看,主节点出现了问题我们还需要通过人工干预的方式把从节点设为主节点,还要通知应用程序更新主节点地址,这种方式非常繁琐笨重, 而且主节点的读写能力都十分有限,有没有较好的办法解决这两个问题,哨兵机制就是针对第一个问题的有效解决方案,第二个问题则有赖于集群!哨兵的作用就是监控 Redis 系统的运行状况,其功能主要是包括以下三个
1. 监控(Monitoring): 哨兵(sentinel) 会不断地检查你的 Master 和 Slave 是否运作正常。
2. 提醒(Notification): 当被监控的某个 Redis 出现问题时, 哨兵(sentinel) 可以通过 API向管理员或者其他应用程序发送通知。
3. 自动故障迁移(Automatic failover): 当主数据库出现故障时自动将从数据库转换为主数据库。
### 哨兵的原理
Redis 哨兵的三个定时任务,Redis 哨兵判定一个 Redis 节点故障不可达主要就是通过三个定时监控任务来完成的:
- 每隔 10 秒每个哨兵节点会向主节点和从节点发送"info replication" 命令来获取最新的拓扑结构
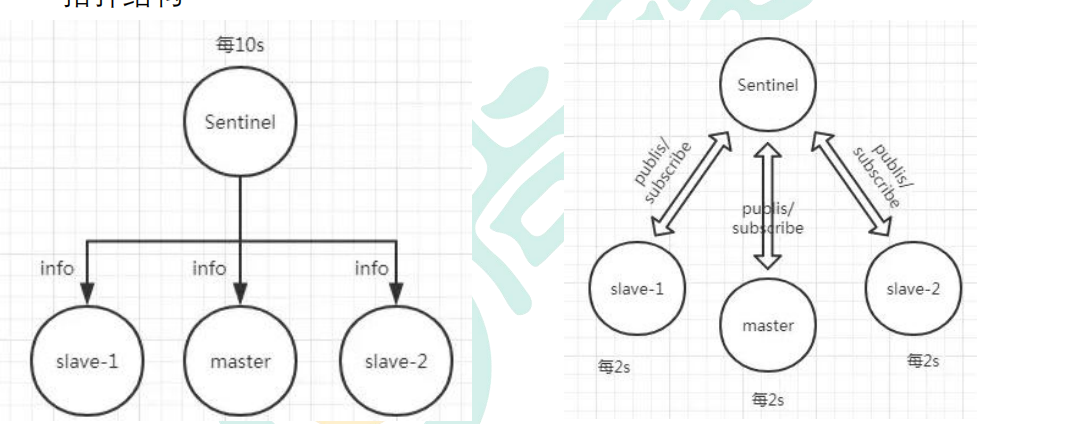
- 每隔 2 秒每个哨兵节点会向 Redis 节点的_sentinel_:hello 频道发送自己对主节点是否故障的判断以及自身的节点信息,并且其他的哨兵节点也会订阅这个频道来了解其他哨兵节点的信息以及对主节点的判断
- 每隔 1 秒每个哨兵会向主节点、从节点、其他的哨兵节点发送一个 “ping” 命令来做心跳检测
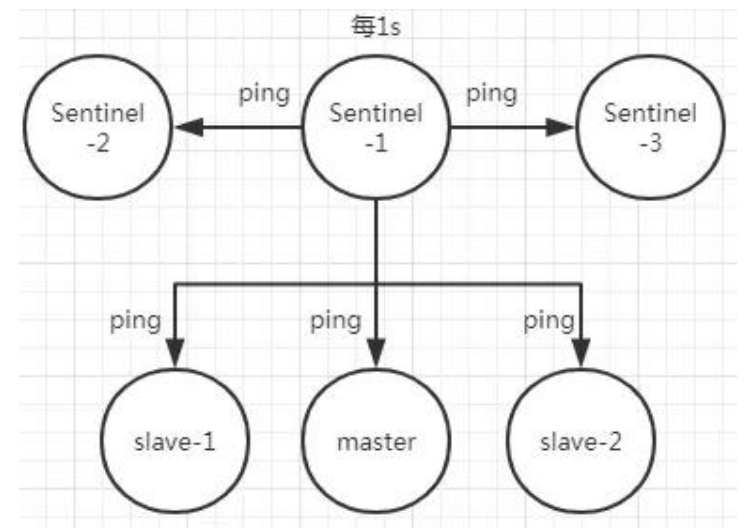
> 如果在定时 Job3 检测不到节点的心跳,会判断为“主观下线”。如果该节点还是主节点那么还会通知到其他的哨兵对该主节点进行心跳检测,这时主观下线的票数超过了<quorum>数时,那么这个主节点确实就可能是故障不可达了,这时就由原来的主观下线变为了“客观下线”。
> 故障转移和 Leader 选举如果主节点被判定为客观下线之后,就要选取一个哨兵节点来完成后面的故障转移工作,选举出一个 leader,这里面采用的选举算法为 Raft。选举出来的哨兵 leader 就要来完成故障转移工作,也就是在从节点中选出一个节点来当新的主节点,这部分的具体流程可参考引用. [《深入理解 Redis 哨兵搭建及原理》](https://blog.csdn.net/nuomizhende45/article/details/82831966)
## Redis-Cluster
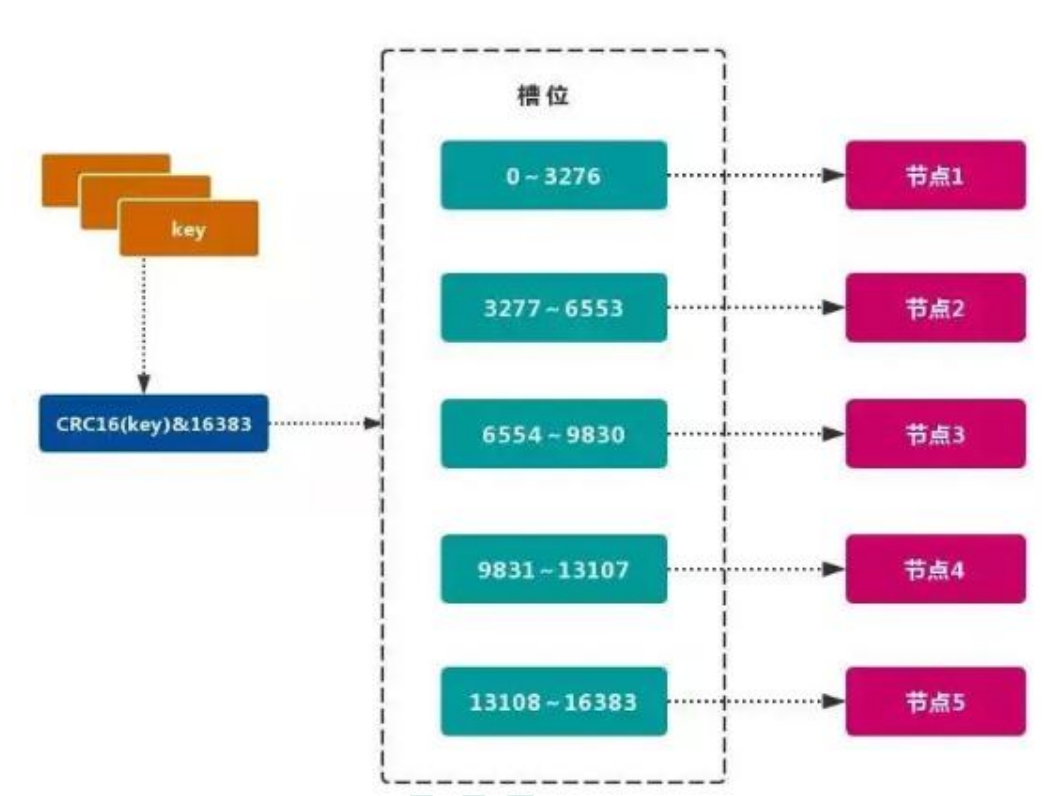
Redis 的官方多机部署方案,Redis Cluster。一组 Redis Cluster 是由多个 Redis 实例组成,官方推荐我们使用 6 实例,其中 3 个为主节点,3 个为从结点。一旦有主节点发生故障的时候,Redis Cluster 可以选举出对应的从结点成为新的主节点,继续对外服务,从而保证服务的高可用性。那么对于客户端来说,知道知道对应的 key 是要路由到哪一个节点呢?Redis Cluster把所有的数据划分为 16384 个不同的槽位,可以根据机器的性能把不同的槽位分配给不同的 Redis 实例,对于 Redis 实例来说,他们只会存储部分的 Redis 数据,当然,槽的数据是可以迁移的,不同的实例之间,可以通过一定的协议,进行数据迁移。
### 槽
Redis 集群的功能限制;Redis 集群相对 单机 在功能上存在一些限制,需要 开发人员 提前了解,在使用时做好规避。[JAVA CRC16 校验算法](https://blog.csdn.net/key_xyes/article/details/93614373?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task)
- key 批量操作 支持有限。
- 类似 mset、mget 操作,目前只支持对具有相同 slot 值的 key 执行 批量操作。对于 映射为不同 slot 值的 key 由于执行 mget、mget 等操作可能存在于多个节点上,因此不被支持。
- key 事务操作 支持有限。
- 只支持 多 key 在 同一节点上 的 事务操作,当多个 key 分布在 不同 的节点上时 无法 使用事务功能。
- key 作为 数据分区 的最小粒度
- 不能将一个 大的键值 对象如 hash、list 等映射到 不同的节点。
- 不支持 多数据库空间
- 单机 下的 Redis 可以支持 16 个数据库(db0 ~ db15),集群模式 下只能使用 一个 数据库空间,即 db0。
- 复制结构 只支持一层
- 从节点 只能复制 主节点,不支持 嵌套树状复制 结构。
- 命令大多会重定向,耗时多

### 一致性Hash
一致性哈希 可以很好的解决 稳定性问题,可以将所有的 存储节点 排列在 收尾相接 的Hash 环上,每个 key 在计算 Hash 后会 顺时针 找到 临接 的 存储节点 存放。而当有节点 加入 或 退出 时,仅影响该节点在 Hash 环上 顺时针相邻 的 后续节点。
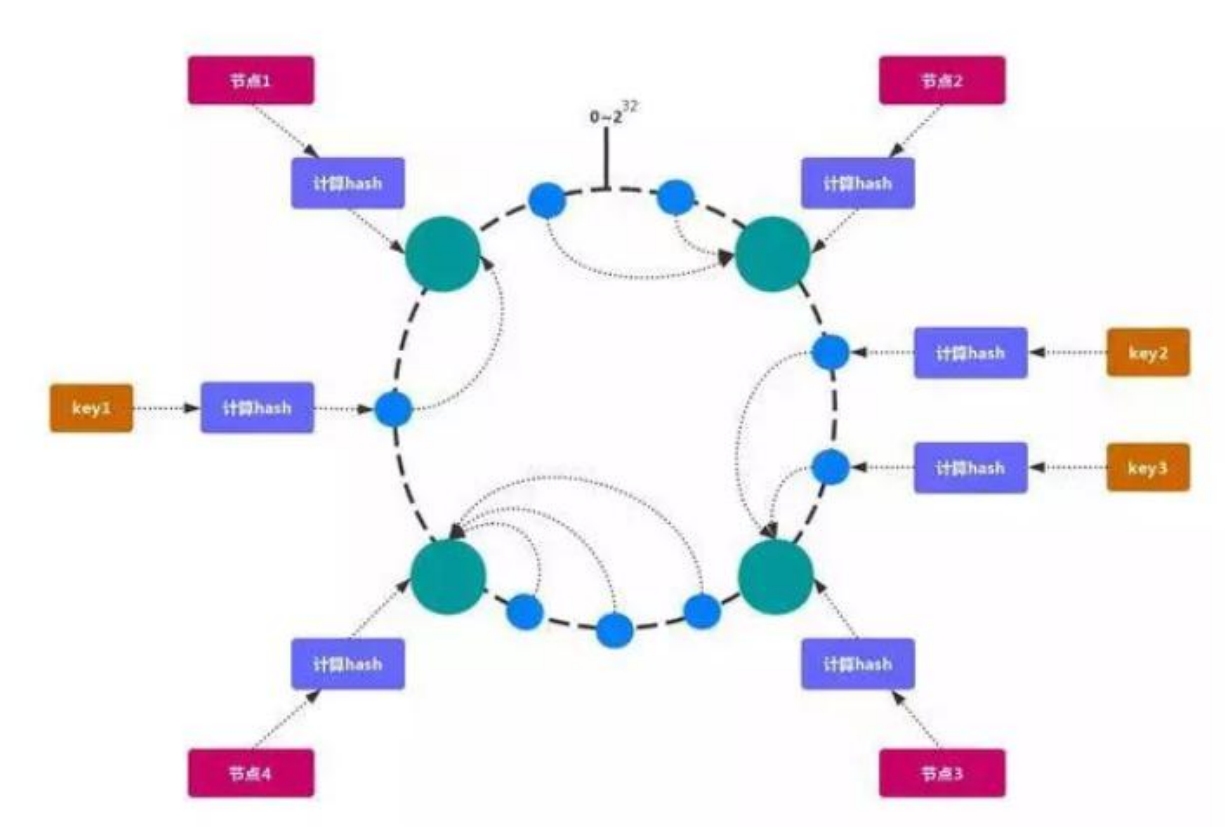
#### Hash 倾斜
如果节点很少,容易出现倾斜,负载不均衡问题。一致性哈希算法,引入了虚拟节点,在整个环上,均衡增加若干个节点。比如 a1,a2,b1,b2,c1,c2,a1 和 a2 都是属于 A 节点的。解决 hash 倾斜问题
> **这个模型主要是对哈希槽的一个抽象**
## 构建集群
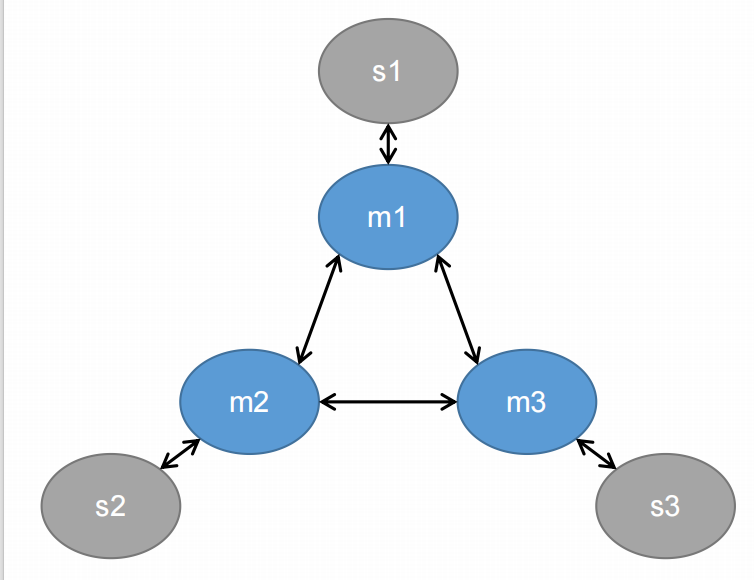
> 为什么要这么多主节点呢? 主要是为了主节点之间做数据分片, 为什么要从节点, 主要是主从复制, 避免主节点宕机导致的数据丢失
1. **把所有的存储卷都准备好**

2. **准备好每一个configMap**

3. **创建有状态服务**
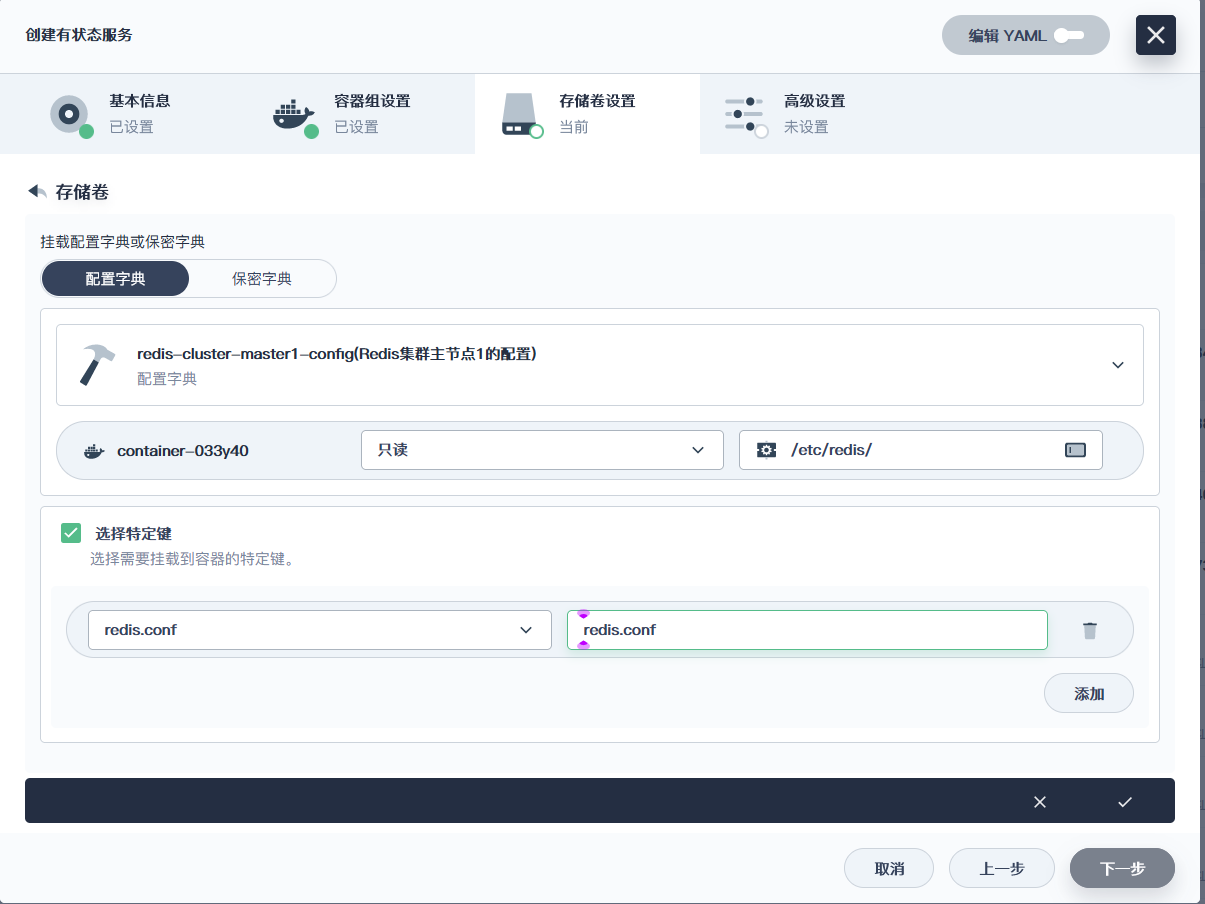
4. **创建完了就更新配置**

5. **删除容器**
6. **查看日志**

> **按照上面的逻辑, 把6个节点创建出来**
7. **随便进入一个几点创建集群**
> **注意: 这里写的是容器组IP地址**
```shell
redis-cli --cluster create 10.244.1.72:6379 10.244.1.80:6379 10.244.1.73:6379 10.244.0.208:6379 10.244.0.220:6379 10.244.0.211:6379 --cluster-replicas 1
```
> **注意, 这里写容器的IP地址是无所谓的, 因为底层他帮我们换成了域名的形式, 刚开始会报错, 报错具体是说哈希槽没分配好, 但是过一会就好了**
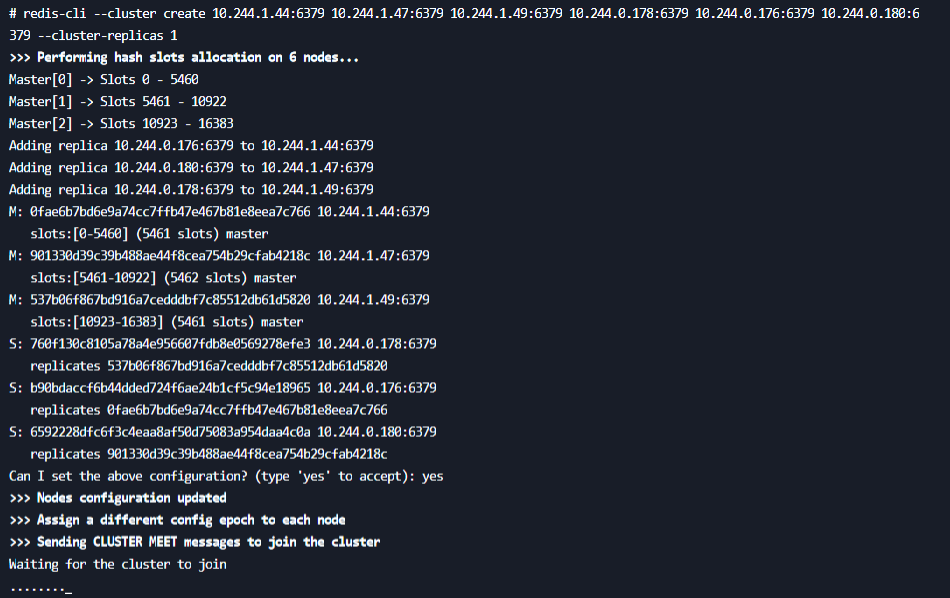
**这里谁是谁的从无所谓了**
> **这里直接ctrl+c出来就可以了, 否则会等很久, 他就一直....., 事后我发现所有都可以连接的上**
8. 连接集群
```shell
redis-cli -c -h <主机的ip> -p <主机的端口号(默认6379)>
```
```shell
cluster info; # 获取集群信息
cluster nodes; # 获取集群节点
```
# RabbitMQ专题
## 集群形式
- 普通模式(默认)
对于普通模式,集群中各节点有相同的队列结构,但消息只会存在于集群中的一个节点。对于消费者来说,若消息进入 A 节点的 Queue 中,当从 B 节点拉取时,RabbitMQ 会将消息从 A 中取出,并经过 B 发送给消费者。
应用场景:该模式各适合于消息无需持久化的场合,如日志队列。当队列非持久化,且创建该队列的节点宕机,客户端才可以重连集群其他节点,并重新创建队列。若为持久化,只能等故障节点恢复。
- 镜像模式
与普通模式不同之处是消息实体会主动在镜像节点间同步,而不是在取数据时临时拉取,高可用;该模式下,mirror queue 有一套选举算法,即 1 个 master、n个 slaver,生产者、消费者的请求都会转至 master。
应用场景:可靠性要求较高场合,如下单、库存队列。
缺点:若镜像队列过多,且消息体量大,集群内部网络带宽将会被此种同步通讯所消耗。
(1)镜像集群也是基于普通集群,即只有先搭建普通集群,然后才能设置镜像队列。
(2)若消费过程中,master 挂掉,则选举新 master,若未来得及确认,则可能会重复消费。
### 总结与知识点
#### 为什么不用普通模式?
> 因为普通模式只同步元数据信息, 不同步消息, 如果某个机器故障, 就会出现单点故障问题, 具体来说就是, 里面的消息全都丢失了, 这非常的危险, 因此, 我们不可以用普通模式, 只能用镜像模式, 镜像模式同步了数据, 即使单点故障了, 数据也不会丢失, 数据在其他节点保存着
#### 为什么要有Cookie?
> 我们可以这么理解, 节点之间互相通信, 必须要有通信的凭证, 否则别人会恶意注入, 而这个凭证就是Cookie, 有Cookie也能标识是这个集群的