SpringCache的整合
# SpringCache的整合
## BUG修复
### 非法参数异常
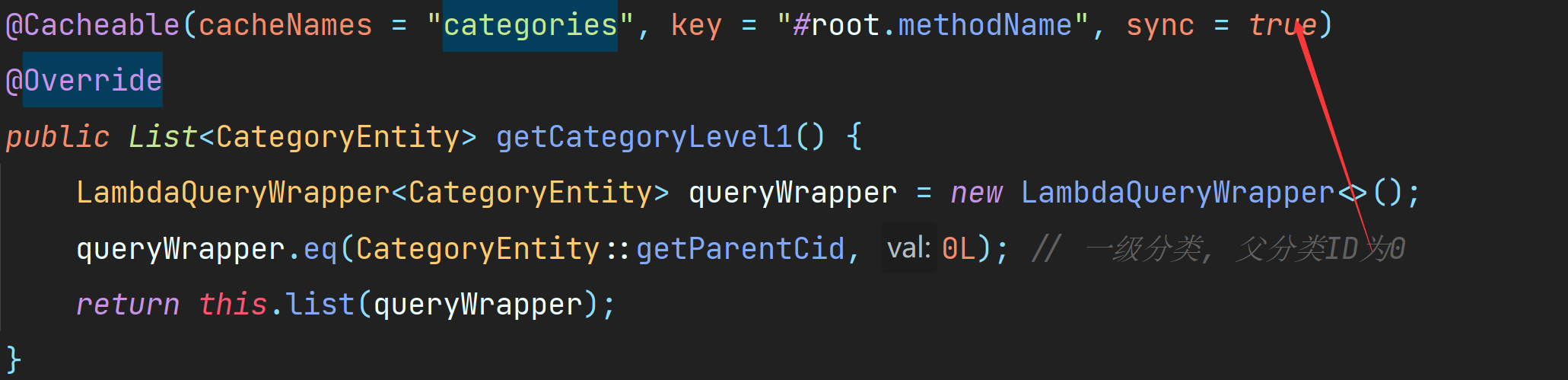
> `java.lang.IllegalArgumentException: Null key returned for cache operation (maybe you are using named params on classes without debug info?) Builder[public java.util.List com.junjie.bitmall.product.service.impl.CategoryServiceImpl.getCategoryLevel1()] caches=[categories] | key='#methodName' | keyGenerator='' | cacheManager='' | cacheResolver='' | condition='' | unless='' | sync='false'`
> ***原因是少了个root, 是`#root.methodName`***
## 环境搭建
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
```
```yml
spring:
cache:
type: redis
```
```java
@EnableCaching
```
## SpringCache的介绍
- Spring3.1开始定义了`org.springframework.cache.Cache`和 `org.springframework.cache.CacheManager`接口来统一不同的缓存基数, 并支持使用注解来简化开发
### 整体架构
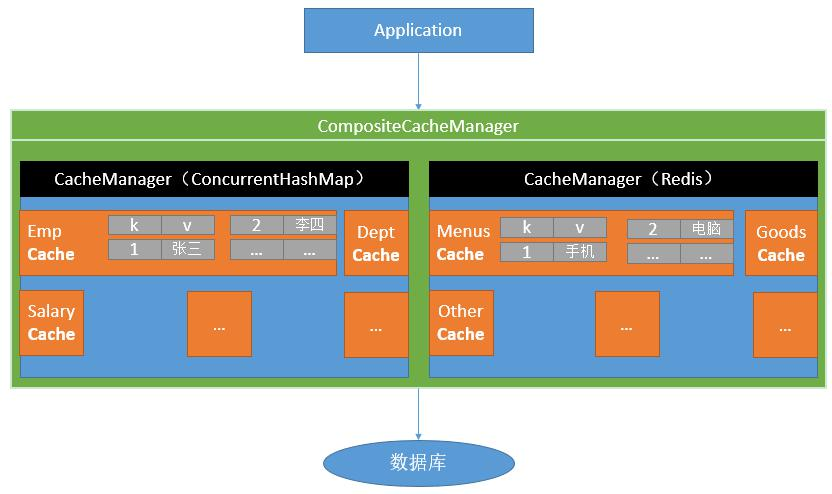
#### 缓存管理器接口
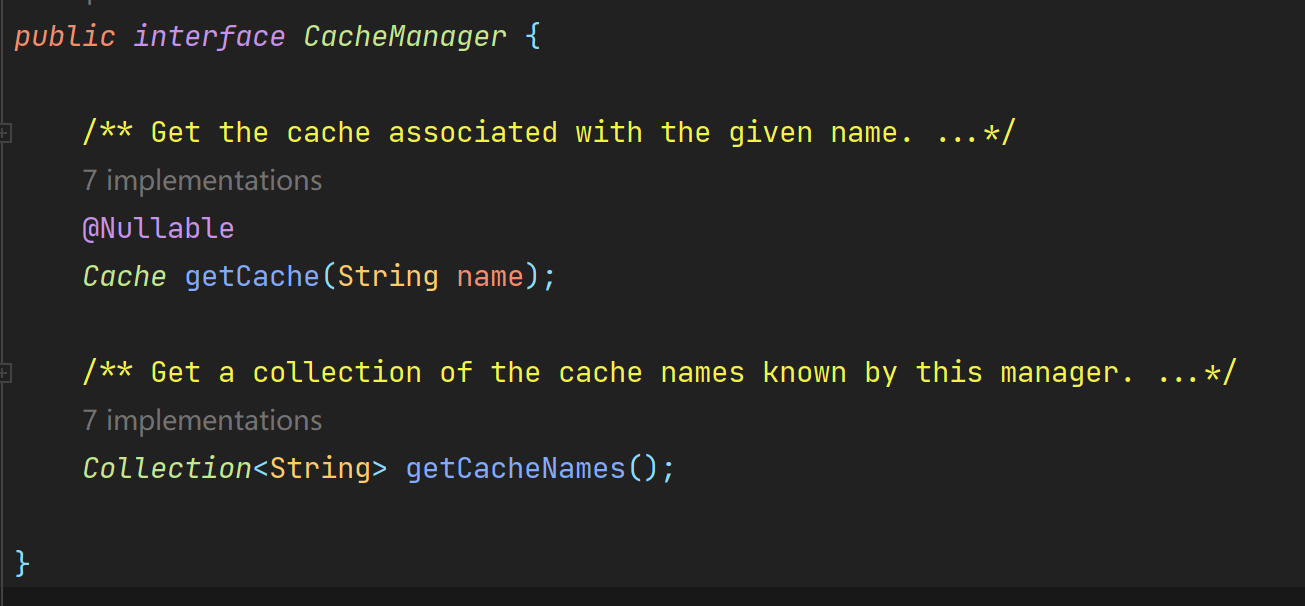
1. 可以通过缓存的名字获取指定的缓存
2. 可以获取所有缓存名字的集合
#### 缓存接口
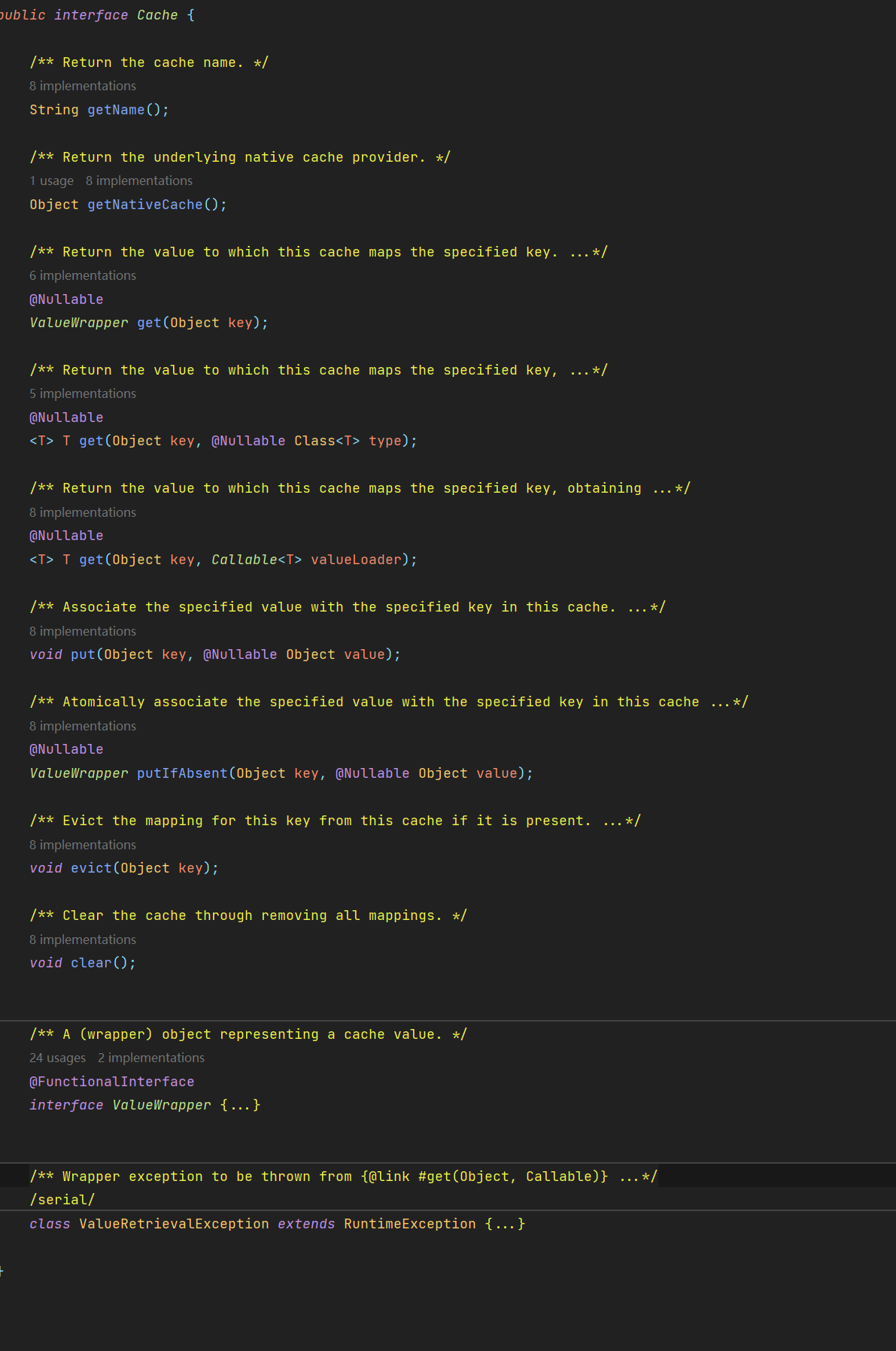
上述接口定义了缓存的CRUD操作
#### `ConcurrentMapCacheManager`和`ConcurrentMapCache`总结(了解即可)
1. 该缓存管理器本质上是一个`ConcurrentHashMap`, 每一个value都是`ConcurrentHashMap`, `key`是缓存的名字, 通过父接口, 通过循环设置缓存的名字, 也通过get获取指定缓存
2. 该缓存里面定义了CRUD操作, 都是按照着父接口来的, 本质是对`ConcurrentHashMap`的CRUD操作
## 自动配置类配置的流程
[流程](https://www.processon.com/embed/64cf5e4119ad082f10a47894)
### 缓存注解
|注解|说明|
|--|--|
|`@Cacheable`|查询是否有对应的缓存, 若有则直接反序列化并返回, 不调用方法, 若没有, 则调用方法, 将返回值结果序列化后存储到缓存中|
|`@CacheEvict`|调用完对应的更新方法后, 指定的缓存删除(失效策略)|
|`@cCachePut`|调用完对应的更新方法, 将返回值序列化后覆盖到缓存中对应的数据(双写策略)|
|`@Caching`|批量操作, 可以写多个上述的操作|
## 开发要点
### 默认行为
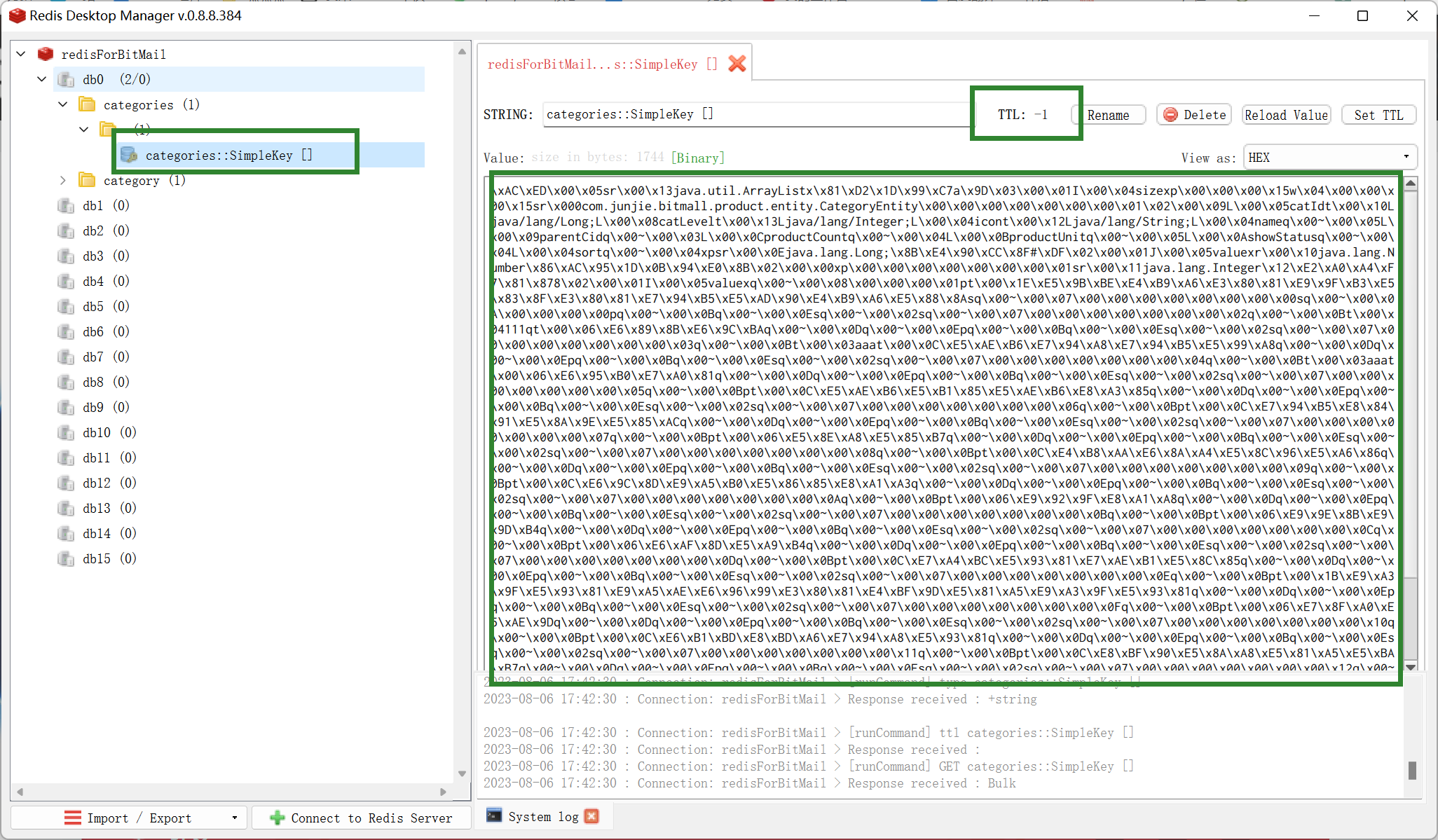
1. key可以自动生成, 但是这个key可读性很差, 不能直到这个是谁的缓存
2. value是Java序列化的结果, 只能被Java读取, 跨平台性差
3. 默认的过期时间为-1, 相当于永不过期, 没能保证最终一致性
### 优化方案
1. 自定义key, 可以将当前方法名作为key, 注意, key里面写的是一个SPEL表达式, 单引号可以避免被SPEL解析
2. 自定义缓存管理器配置, 设置过期时间和value的序列化形式
## 最佳实战
```yml
spring:
cache:
type: redis
redis:
time-to-live: 86400000 # 以毫秒为单位, 默认缓存一天
use-key-prefix: true # 开启前缀, 前缀可以开启目录结构, 更好的管理, 使用默认前缀, 便于运用明明空间
cache-null-values: true # 缓存空值, 避免缓存穿透
```
```java
@Bean
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) { // 组件注入
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
config = config.serializeKeysWith(RedisSerializationContext
.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext
.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())); // 该解析器支持泛型
// 下面这些代码的目的是为了读取yaml里面的数据, 然后条件设置, 如果没有下面的代码, yaml里面的操作不会生效
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive()); // 过期时间以毫秒为单位
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
```
1. 使用前缀且前缀使用默认的, 这样方便管理, 自定义不好, 导致缓存名字丧失了意义
> 没有前缀, 全都堆在一起, 不好管理, 自定义也没有默认的好, **同一类型的数据需要放在同一分区, 即缓存名字需要一致, 便于失效策略一起将缓存小面**
2. 设置过期时间, 抱枕贵重一致性, 开启缓存空数据, 避免缓存从穿透
3. 将key和value的序列化改为String和Json的, 保证可视化和跨平台性
4. 记得拷贝源码, 使得yaml被启用
5. 使用的时候一定要指定key和缓存名字, 一定要有规则
## 引入Cache后, 缓存三大问题如何解决
### 缓存穿透问题

### 缓存雪崩问题
> 以前的方式是加上一个随机时间, 保证过期时间不一样避免缓存雪崩问题, 但是, 加上随机时间有可能弄巧成拙, 比如3+1 过了一秒 3+0, 后面是基数后添加的时间, 前面是基数时间, 本来过期时间不一样的, 过了随机时间反而过期时间一样了, 反而导致了雪崩问题
> **因此, 缓存雪崩问题不需要特意处理, 缓存雪崩问题出现的机率很小**
### 缓存穿透问题
### 针对于缓存穿透问题的深入研究
#### 源码
[源码](https://www.processon.com/embed/64d1a0dd19ad082f10a6f2cf)
#### 为什么允许使用本地锁
> **之前我们讲过一个问题, 本地锁会导致少量的并发, 并不符合规则, 但是, 毕竟分布式的节点有限, 并发量有限, 而且使用该方法可以大大减少代码开发难度, 这种牺牲是允许的, 而且分布式锁的性能损耗也大, 这里不采取分布式锁**
## 十万个为什么
### 为什么要有缓存名字?
> 因为一个缓存管理器下面有很多的缓存, 为了方面管理, 因此每一块缓存都要给对应的名字
> **从Redis的角度而言, 一个缓存名字对应着一块目录, 不同的缓存名字组成不同的目录, 更方面我们管理**
# SpringCache的最佳实战
1. 读多写少, 只需要保证最终一致性, 都适合使用SpringCache
2. 如果需要强一致性, 则需要自己用分布式锁, 自己采取失效策略, 自己采取读写锁等, 不适合用SpringCache
3. 简而言之, 业务逻辑比较简单, 可以使用SpringCache, 比较复杂, 不建议使用, 具体业务具体分析