本地事务与分布式事务
# 本地事务与分布式事务
## 本地事务在分布式下的问题
> 订单微服务调用库存微服务锁定库存
### 场景一
> 若订单微服务在执行的过程中出现了异常, 由于异常机制, 后面的库存微服务不会被调用, 订单也会被回滚
> 整体而言没有任何的问题
### 场景二
> 若订单微服务调用的库存微服务发生了异常, 库存微服务的本地事务会将所有的锁定库存操作均回滚, 通过判断返回的状态码, 订单微服务也可以手动抛异常实现回滚
> 整体而言, 没有问题
### 场景三
> 若网络传输比较缓慢, 当订单微服务调用库存微服务时, 可能会触发Feign的超时异常, 此刻, 订单微服务会因为该异常回滚, 但是库存很可能没有发生异常, 是正常执行的, 就会导致订单不存在而锁定了库存
> 整体而言, 有数据不一致问题!
### 场景四
> 若订单微服务调用库存微服务没有任何问题, 但是, 后续的执行中出现了异常, 就会导致订单的回滚, 而库存是没有办法回滚的
> 整体而言, 有数据不一致问题!
### 结论
> 在分布式场景下, 本地事务不能保证数据的一致性, 我们需要依赖分布式事务
## 本地事务的复习
### 1. 事务的基本性质(ACID)
#### Atomic(原子性)
> 原子性可以理解为要么全部成功, 要么全部不成功, 和Redis的原子性有一点不同
#### Consistency(一致性)
> 一致性可以理解为, 比如当前项目中的订单和锁定, 有订单的时候必须要锁定库存, 不能有订单不锁定或锁定没订单
#### Isolation(隔离性)
> 隔离性可以理解为不同的事务之间互相不干扰
#### Durabilily(持久性)
> 持久性可以理解为如果事务提交了, 数据库一定会有这个数据, 无论什么情况, 都会有, 一定会有
### 2. 事务的隔离级别
#### READ UNCOMMITTED (读未提交)
> 读未提交, 顾名思义即 事务A 读取了 事务B没有提交的数据
> 这会导致脏读和脏写的情况
#### READ COMMITTED (读已提交)
> 读已提交, 顾名思义即 事务A 读取了 事务B已提交的数据
> 这会导致不可重复读的情况, 即读着读着突然某些数据发生了改变
#### REPEATABLE READ (可重复读)
> 可重复读, 顾名思义即 事务A 读取某个数据, 该数据永远都不变, 即使事务B提交了该数据的最新情况
> 这会导致幻读的情况, 即读着读着突然多了条数据
#### SERIALIZABLE (序列化)
> 序列化, 顾名思义即 只有一个事务可以进行对数据库的操作
> 序列化解决了所有的问题, 但是, 几乎没有并发, 肯定是不予考虑的
#### 总结
> MySQL事务的默认隔离级别是READ COMMITED(读已提交)
### 3. 事务的传播行为
- PROPAGATION_REQUIRED
- 可以理解为被调用的方法和调用的方法共享同一个事务
- PROPAGATION_REQUIRES_NEW
- 可以理解为被调用的方法和调用的方法采用不同的事务, 这两个方法的回滚互相不干扰, 遵循隔离性
- 其他事务的传播行为
#### 关于事务传播行为的相关要点
##### 配置问题
> 若传播行为为PROPAGATION_REQUIRES_NEW, 那么这个事务的配置由当前方法决定, 不受被调用的方法的设置所影响
> 若传播行为为PROPAGATION_REQUIRED, 那么这个事务的配置由被调用的方法决定, 当前方法所有的配置都会失效
### 事务失效问题
#### 什么是事务失效问题
```java
@Transactional
public void a() {
}
@Transactional
public void b() {
}
@Transactional
public void c() {
}
```
> 上面声明了三个`@Transactional`, 即目标想要声明三个事务, 但是, 默认会存在一个事务失效问题, 即上面的b和c方法实际上会绕过代理对象, 相当于如下代码
```java
@Transactional
public void a() {
b();
c();
}
```
因此, 这样会导致b()方法和c()方法的事务失效
#### 如何解决事务失效问题
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
```
```java
@EnableAspectJAutoProxy(exposeProxy = true) // 向外暴露代理对象
public class BitmallOrderApplication {
```
```java
@Transactional
public void test() {
OrderSubmitServiceImpl service = (OrderSubmitServiceImpl) AopContext.currentProxy();
service.submitOrder();
}
```
> 放心强转为当前对象
## 为什么需要有分布式事务
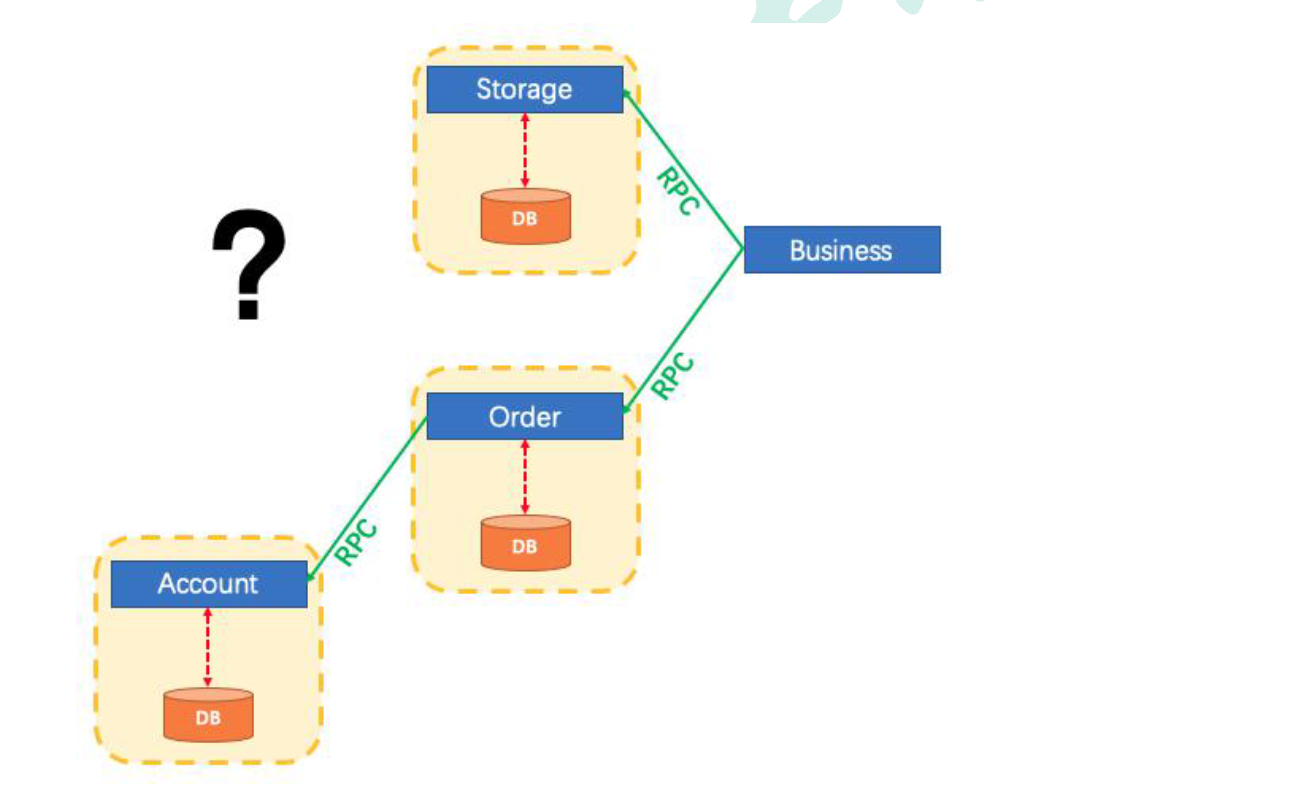
> 分布式系统经常出现的异常机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的 TCP、存储数据丢失等, 都需要分布式事务的参与解决
## CAP定理
### Consistency(强一致性)
> 强一致性可以理解为, 如果某个节点读取了一个数据, 那么所有的节点的该数据都应该一样, 如果有一个不一样, 整个集群都不可用, 保证访问所有的节点都是一样的
### Availability(高可用性)
> 高可用性可以理解为, 如果某个节点宕机或者发生了数据不一致问题, 集群还是可用的, 会出现短暂的数据不一致问题
### Partition tolerance(分区容错性)
> 分区容错性可以理解为, 如果集群中的某几个节点因为网络传输问题断开, 其他节点依旧可以相互传输数据, 断开的节点也可能存在网络传输
### 总结
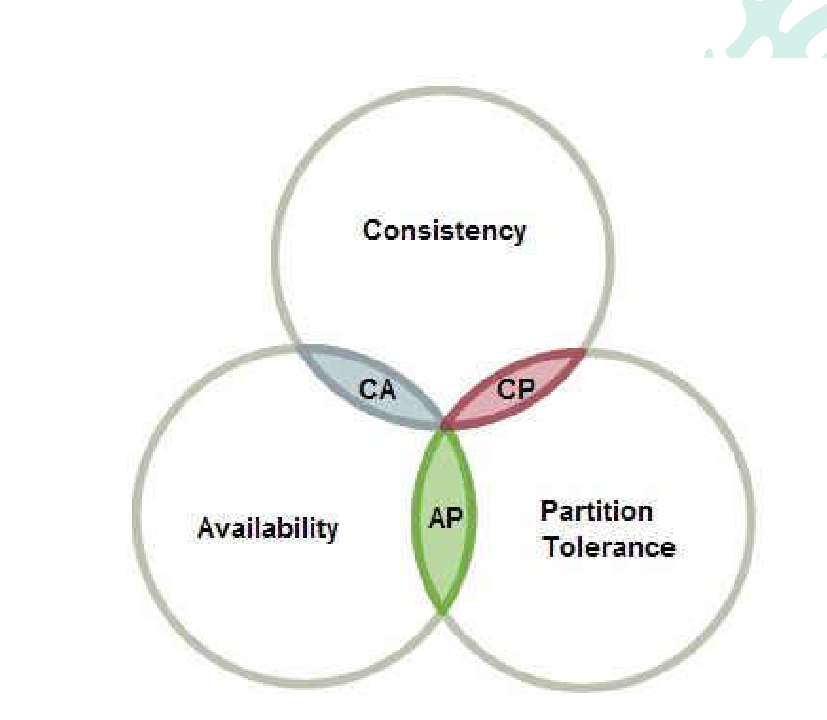
> CAP可能三者均满足, 大部分场景下, 要么满足CP, 要么满足AP
#### 为什么CA不能互存?
> C代表着强一致性, 如果一个节点的数据发生了不同步, 那么整个集群不可用, 而A恰恰相反, 它允许一两个节点出现数据不一致的问题, 因此, 这两者的理论互相矛盾, 因此, CA不可能同时出现
#### 为什么一定满足分区容错性?
> 如果不满足分区容错性, 如果网络一旦出现波动, 那么节点之间就无法同步数据, 这是一个很严重的问题
## Raft算法的说明
[Raft算法流程图](http://thesecretlivesofdata.com/raft/)
### 角色说明
> 随从: 所有的节点的初始状态都是随从
> 候选者: 如果节点消耗完了自选时间, 自动称为候选者
> 领导者: 领导者由候选者中大多数票数的节点产生, 作为信息传输的第一站
### 什么是自旋时间?具有什么样的特性?
> 每一个随从都有一个**随机的自选时间**, 当自旋时间消耗殆尽时, 该节点自动成为一个候选者
> 当节点收到候选者请求或者领导者的生命请求的时候, 自旋时间都会被重置
### 领导选举大致流程?
#### 简单情况
> 每一个节点都会有一个150~300ms的随机自旋时间, 当自旋时间被耗尽的时候, 自动成为候选者, 发送候选请求, 自己会投自己一票, 响应的请求都会成为票数, 获得大多数票数的一方(超过1/2)会称为领导者
> 领导者会一直发送生命请求, 不断重置着随从的自旋时间
> 如果领导者宕机, 那么随从的自旋时间没有办法被重置, 那么和上面一样, 自旋时间先消耗完的一方作为新的领导者
#### 复杂情况
> 如果两个或多个候选者的票数一致, 那么这一轮的选举情况作废, 注意, 此刻无论是候选者还是随从都还存在自旋时间, 自旋时间一到, 继续重复上述的方法发送选举请求, 直到有一个候选者得到超过1/2票数称为领导者
#### 更复杂的情况
> 如果出现了分区故障, 一共会出现两种情况, 该分区有领导者, 该分区没有领导者, 如果该分区有领导者, 因为生命请求的缘故, 并不会产生新的领导者
> 如果当前分区没有领导者, 当前分区仍需要获取大多数票数的获选者才能称为领导者, 注意, 这个大多数并不以当前分区计算, 应该以总量计算, 即如果变成了3 - 2, 大多数还是3
> 如果分区故障恢复了, 就会出现两个领导者的情况, 那么, 选举轮次较多的领导者称为最终的领导者
### 日志复制的大致流程?
#### 简单情况
> 当领导者收到客户端的请求的时候, 领导者会将操作结果存放到日志中, 该日志的状态是未提交状态, 因为领导者会定期发送生命请求来维持随从, 因此, 未提交的日志会随着生命请求发送给其他随从, **因此, 未提交的日志并不会马上发送给随从**, 当领导者手动随从的确认应答后, 领导者提交日志, 做出更改, 并通过下一次生命请求让随从也提交日志
#### 复杂情况
> 如果分区故障了, 5个节点独立出来了两个, 那么它们永远提交不了日志, 因为, **提交日志的前提是获得大多数节点的响应**, 两个节点最多两个响应, 因此, 永远都提交不了
#### 最终情况
> 因为是轮次最多的称为最终的领导者, 其如果提交了数据, 那么下一次生命请求会将所有回来的节点都同步到当前数据
### 深化理解
[可操作Raft流程](https://raft.github.io/)
### 从Raft的角度说明CA不共存
> Raft本质上是保持强一致性, 如果出现网络分区故障, 那么剩余的几个节点很有可能无法选举出领导者, 会导致这些节点不可用, 违背了高可用, 因此CA不共存
## 面临的问题
对于大多数的互联网场景, 主机众多, 部署分散, 而且现在的集群规模越来越大, 所以节点故障, 网络故障成为常态, 而且要保证服务的可用性达到99.99%, 即需要保证AP, 舍弃CP
## BASE理论
### BA-Basic Available(基本可用)
> 基本可用指分布式系统出现故障时, 允许损失部分功能(例如响应时间, 功能上的损失), 允许损失部分可用性, 需要注意的是**基本可用!=系统不可用**
> 响应时间上的损失, 响应时间上发生了损失, 一般都是离用户最近的节点发生了故障宕机, 导致无法访问该节点, 进而让用户访问更远的节点, 响应时间变长, 但是保障了系统的可用性, 符合基本可用
> 功能上的损失, 例如双十一秒杀, 秒杀功能可能涉及熔断降级进行限流, 导致了部分功能不可用, 其他功能都可用, 符合基本可用
### S-Soft State(软状态)
> 软状态指的是系统允许存在中间状态, 而该中间状态不会影响系统的整体可用性. 分布式存储一般一份数据具有多个副本, 允许不同的副本同步的延迟就是软状态的体现[弱一致性]
### E-Eventual Consistency(最终一致性)
> 最终一致性指的是系统中所有的数据副本经过一段时间后, 最终数据达到一致的情况, 中间可以存在不一致的情况
## 三大一致性理论
### 强一致性
> 数据的强一致性换而言之就是数据的实时一致性, 这要求分布式下所有的数据及其副本都要实时的保持一致, 如果出现了数据不一致的情况, 会导致节点不可用乃至整个集群都不可用
### 弱一致性
> 数据的弱一致性, 不要求数据的实时一致性, 即允许数据出现一段时间的数据不一致, 这些节点仍然可用
### 最终一致性
> 数据的最终一致性, 即在弱一致性的基础上, 当数据发生了不一致时, 过了一段时间, 数据一定会再次一致, 被称为最终一致性
## 分布式事务的几种方案
### 刚性事务和柔性事务
> 刚性事务满足强一致性, 要求数据的实时一致, 符合CP原则
> 柔性事务满足最终一致性, 数据允许出现暂时的不一致, 符合BASE理论
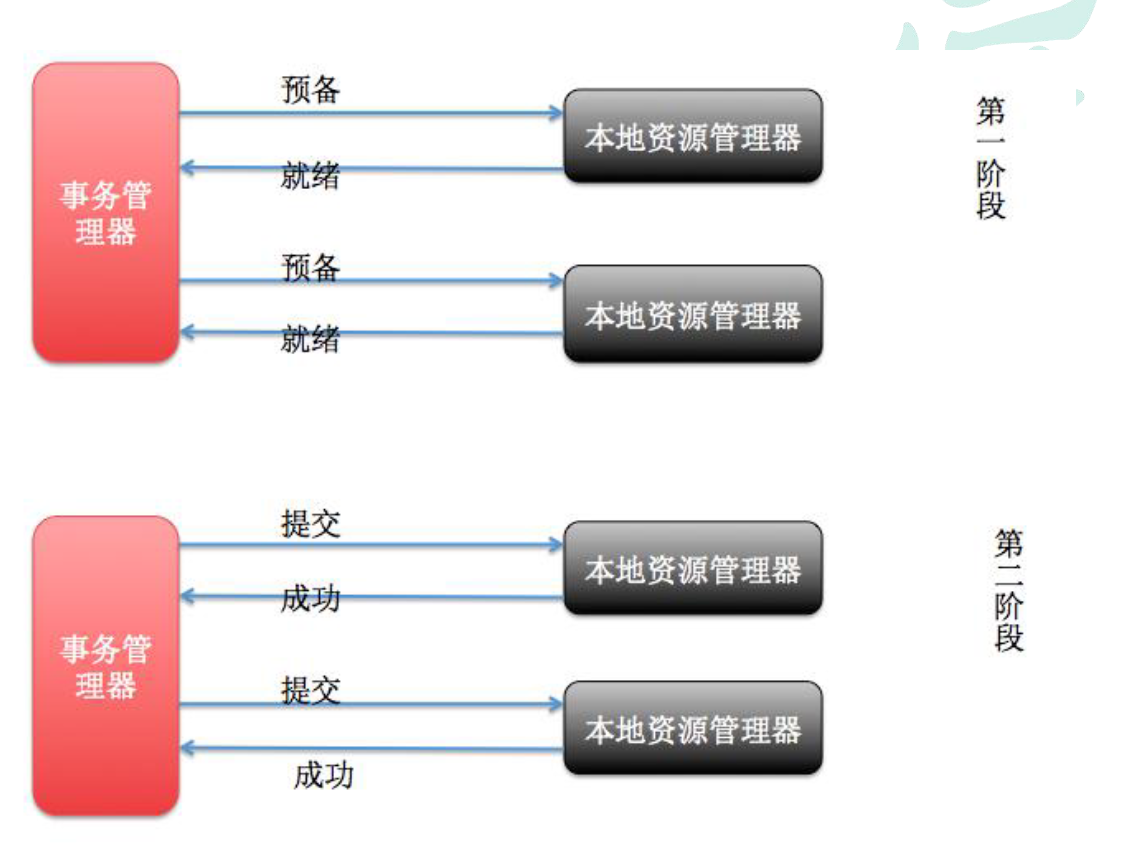
### 刚性事务-2PC模式
> 2PC~2 Phase Commit(二阶段提交), 又被称为XA Transactions
> - 第一阶段: 事务协调器要求每个涉及到事务的数据库预提交此操作, 并反映是否可提交
> - 第二阶段: 事务协调器要求每个数据库提交数据, 其中, 若存在某个数据库否决此次提交操作, 所有操作过的数据库都需要回滚

> - XA协议比较简单, 但是一旦商业数据库实现了XA协议, 使用分布式事务的**成本比较低**
> - <font color="red">**XA性能不理想**</font>, XA的事务采取了锁的形式, 具有串行化的影响, 无法满足高并发的场景, XA的性能因此不理想
> - XA在商业数据库的支持比较理想, **对MySQL的支持不太理想**, MySQL的XA实现, 没有记录prepare阶段日志, 主备切换会导致数据库不一致问题
> - 许多NoSQL数据库也不支持XA
> - 也有3PC, 引入了超时机制(无论是协调者还是参与者, 在向对方发送请求后, 若长时间未收到应答就做出对应的操作)
### 柔性事务-TCC事务补偿方案
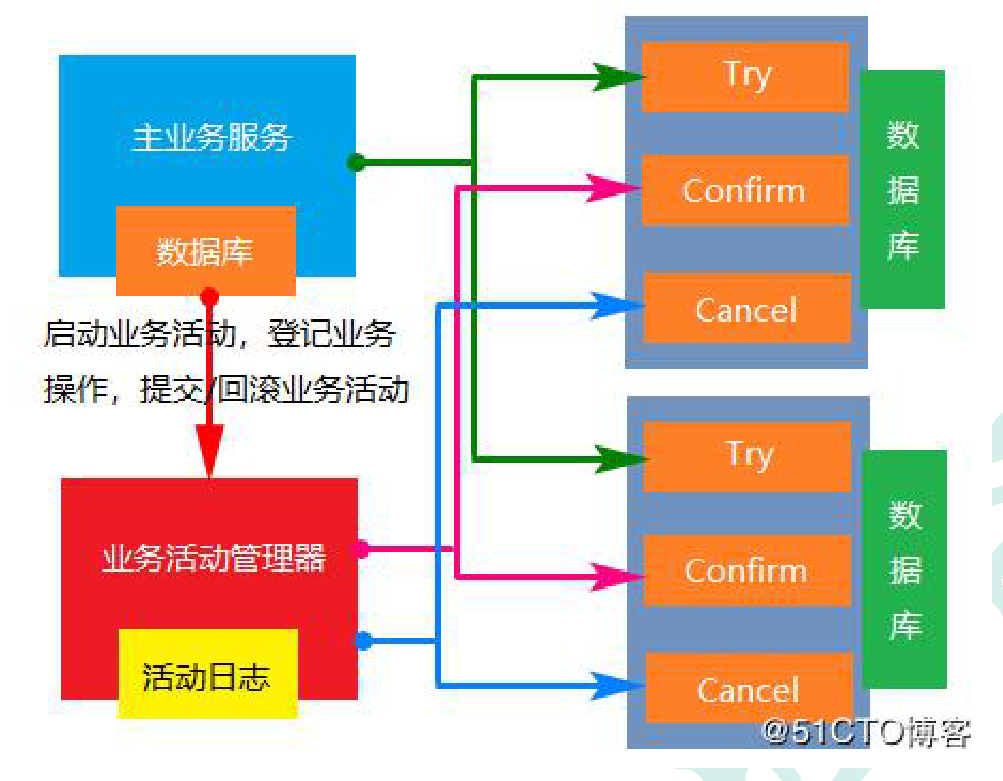
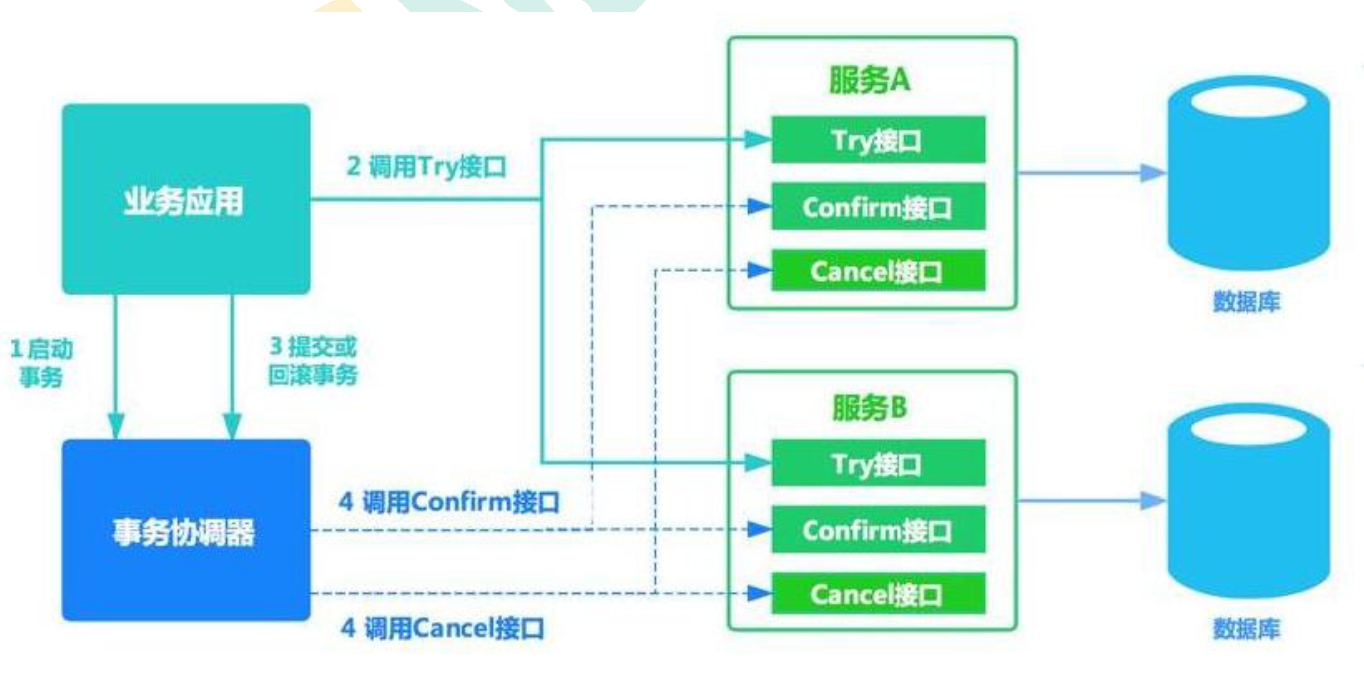
- 第一个阶段, 数据的准备
- 第二个阶段, 数据的提交
- 第三个阶段, 数据的回滚
> TCC事务补偿方案最大的亮点是**事务数据的准备, 提交, 以及回滚都需要手动操作**
### 柔性事务-最大努力通知方案
> 最大努力通知和可靠消息+最终一致性类似, 都是需要依赖于RabbitMQ的延迟队列, 亮点是, 最大努力通知会不间断的发送消息, 确保每一个回滚消费者都能顺利处理消息
### 柔性事务-可靠消息+最终一致性方案(异步确保性)
> 可靠消息+最终一致性的具体实现需要依赖RabbitMQ等消息中间件的加入, 整体的实现思路是如果做出了某个操作, 会将这个操作的日志或其他数据加入延迟队列, 回滚消费者会监听这些队列, 在一段时间后条件判断是否需要回滚, 这就是可靠消息+最终一致性
> 可靠消息需要手动ACK